Computational resources¶
On this page, you will find a description of the ORFEO system architecture, the hardware, and the partitions available on ORFEO.
ORFEO is the cutting-edge data center housed within the AREA Science Park for research ranging from machine learning to material science. Orfeo relies on state-of-the-art computing resources DELL hardware, ensuring reliability and performance. Employing Infiniband for Remote Direct Memory Access (RDMA), Orfeo further amplifies its computational capabilities, enabling seamless communication between computing nodes for enhanced efficiency. ORFEO doesn't just stop at traditional CPUs; it also integrates Graphics Processing Units (GPUs), embracing their parallel processing power.
Computing nodes¶
| Nodes | CPUs | CPU cores | Memory | Network | GPUs per node |
|---|---|---|---|---|---|
| 8 | 2 x AMD EPYC 7H12 (2.6 GHz base, 3.3 GHz boost) |
128 (2x64) |
512 GiB | 1 x 100 Gb/s | N.A. |
| 13 | 2 x AMD EPYC 9374F (3.85 GHz base, 4.1 GHz boost) |
64 (2x32) |
512 GiB | 1 x 200 Gb/s | N.A. |
The cpus installed in these servers are based on the "Rome" and "Genoa" architecture.
For the "Rome" nodes each socket contains eight Core Complex Dies (CCDs) and one I/O die (IOD). Sockets are connected with an infinity fabric that consists of three links at 16GT/s for a theoretical bandwidth of 96 GB/s. Each CCD contains two Core Complexes (CCXs), and Each CCX has four cores and 16 MB of L3 cache. Detailed information on the CPU is also available on wikichip.
The server is configured with 512(16 x 32) GiB of DDR4 RAM at 3200 MT/s. In ORFEO, the 64 cores of each CPU are arranged in 4 NUMA nodes, i.e., 64 GiB of memory per NUMA node.
For the "Genoa" nodes each socket contains eight CCDs and one I/O die. The main differences with the "Rome" nodes are the memory controller (DDR5 up to 4800 MT/s) and the availability of the AVX-512 instruction set. Detailed information on the CPU is also available on wikichip.
The "Genoa" nodes are configured with 512(16 x 32) GiB of DDR5 RAM at 4800 MT/s.
| Nodes | CPUs | CPU cores | Memory | Network | GPUs per node |
|---|---|---|---|---|---|
| 10 | 2 x Intel Xeon Gold 6126 (2.6 GHz base, 3.7 GHz boost) |
24 (2x12) |
768 GiB | 1 x 100 Gb/s | N.A. |
| 2 | 2 x Intel Xeon Gold 6154 (3.0 GHz base, 3.7 GHz boost) |
36 (2x18) |
1536 GiB | 1 x 100 Gb/s | N.A. |
These nodes have cpus based on the "Skylake" architecture. Sockets are connected by an Ultra Path Interconnect (UPI) consisting of three links that can operate at 10.4 GT/s or 9.6 GT/s. Detailed information on the CPUs is also available on wikichip for the 6126 and the 6154 models.
THIN
The thin servers are configured with 768 (12 x 64) GiB of DDR4 RAM at 2666 MT/s, and the 12 cores of each CPU are arranged in 1 NUMA node.
FAT
The fat servers are configured with 1536 (24 x 64) GiB of DDR4 RAM at 2666 MT/s, and the 18 cores of each CPU are arranged in 2 NUMA nodes., i.e., 384 GiB of memory per NUMA node.
| Nodes | CPUs | CPU cores | Memory | Network | GPUs |
|---|---|---|---|---|---|
| 4 | 2 x Intel Xeon Gold 6226 (2.7 GHz base, 3.7 GHz boost) |
24 (2x12) |
256 GiB | 1 x 100 Gb/s | 2 x V100 PCIe 32GiB |
| 2 DGX A100 | 2 x AMD EPYC 7H12 (2.6 GHz base, 3.3 GHz boost) |
128 (2x64) |
1024 GiB | 8 x 100 Gb/s | 8 x A100 SXM 40GiB |
| 3 PowerEdge XE9680 | 2 x Intel(R) Xeon(R) Platinum 8480+ (2.0 GHz base, 3.8 GHz boost) |
112 (2x56) |
1024 GiB | 8 x 200 Gb/s | 8 x H100 SXM 80GiB |
V100
These nodes are based on the "Cascade Lake" architecture. Sockets are connected by an Ultra Path Interconnect (UPI) of three links that can operate at 10.4 GT/s. Detailed information on the CPUs is also available on wikichip for the 6226 model. Multithreading capabilities are enabled on the CPUs.
The servers are configured with 256(8 x 32) GiB of DDR4 RAM at 2933 MT/s. In ORFEO, the 12 cores of each CPU are arranged in 1 NUMA node, i.e., 128 GiB of memory per NUMA node. The GPU numbering is aligned with the NUMA numbering, and one NUMA region contains one GPU. A detailed topological map can be downloaded here. Binding your processes to the NUMA node connected to the GPU might be crucial for achieving optimal performance in your application.
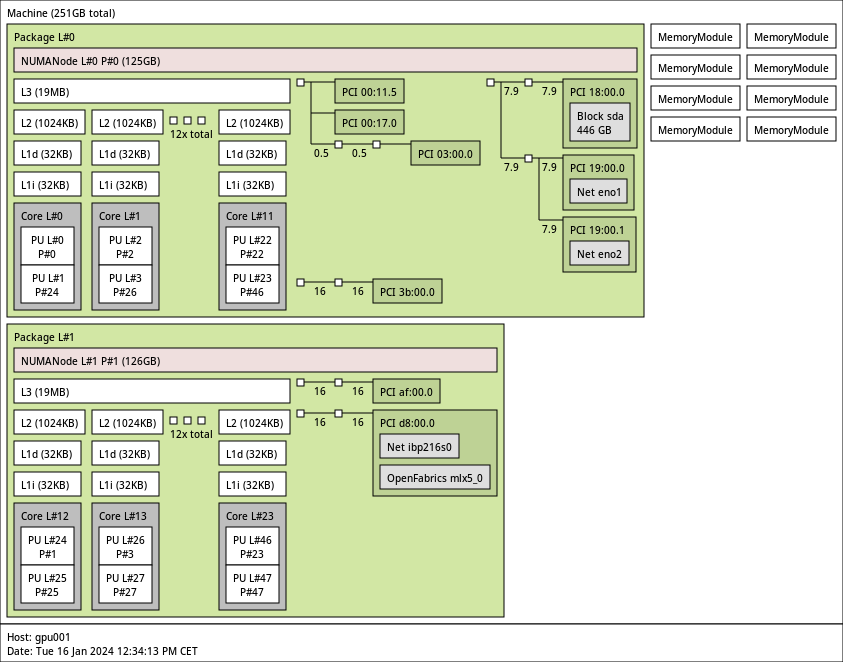{kind=link}
A100
The CPUs installed in these servers are based on the "Rome" architecture. Each socket contains eight Core Complex Dies (CCDs) and one I/O die (IOD). Sockets are connected with an infinity fabric that consists of three links at 16GT/s for a theoretical bandwidth of 96 GB/s. Each CCD contains two Core Complexes (CCXs), and Each CCX has four cores and 16 MB of L3 cache. Detailed information on the CPU is also available on wikichip. Multithreading capabilities are enabled on the CPUs.
The servers are configured with 1024(16 x 64) GiB of DDR4 RAM at 3200 MT/s. In ORFEO, the 64 cores of each CPU are arranged in 4 NUMA nodes, i.e., 128 GiB of memory per NUMA node. The GPU numbering is not aligned with the NUMA numbering, and one NUMA region contains more than one GPU; a detailed topological map can be downloaded here. Be aware that binding your processes to the NUMA node connected to the GPU might be crucial for achieving optimal performance in your application. Each A100 is directly connected to the InfiniBand network with a dedicated card.
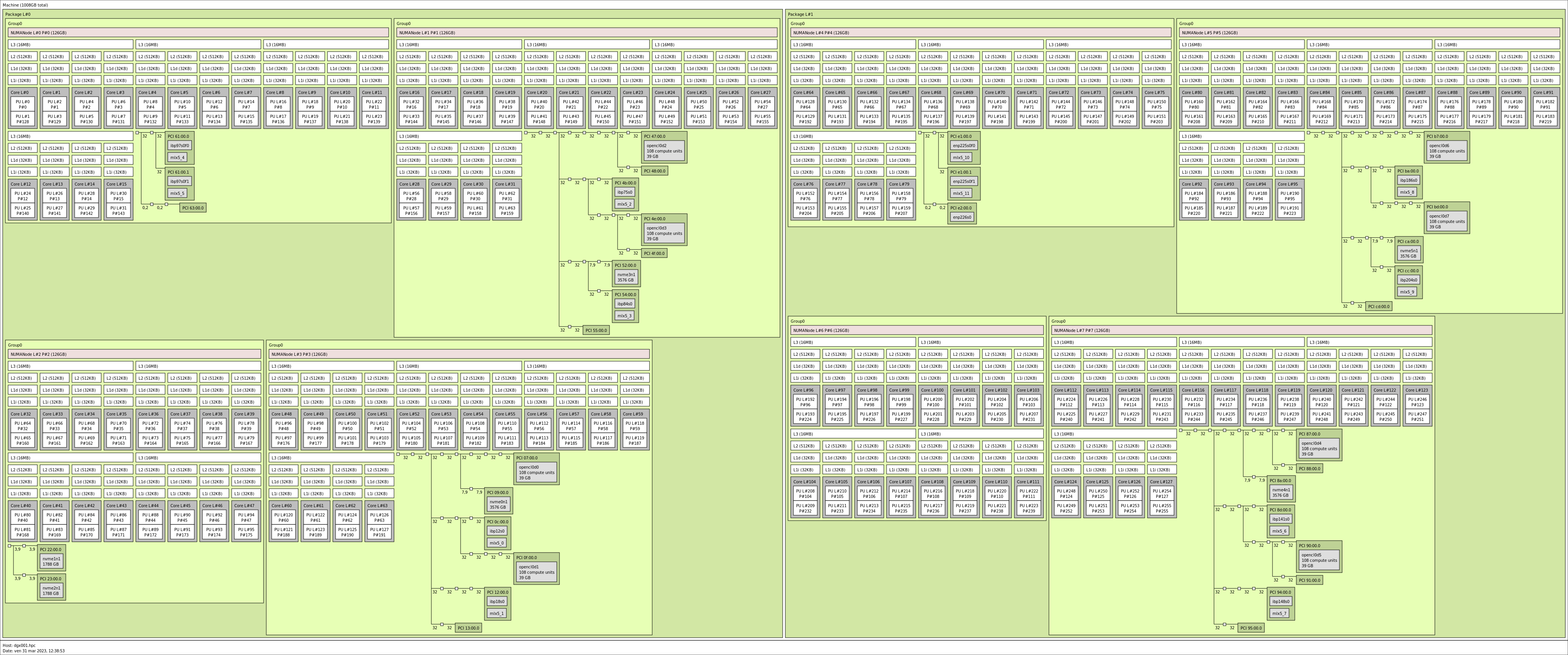{kind=link}
H100
The CPUs installed in these servers are based on the "Sapphire Rapids" architecture. Detailed information on this chip is available on intel website.
The servers are configured with 1024(16 x 64) GiB of DDR5 RAM at 4800 MT/s.
Logical Partitions¶
A partition is a logical grouping of computing resources within a cluster. Slurm (the workload manager deployed in ORFEO) uses partitions to organize and manage the allocation of resources. Each partition typically represents a subset of the cluster's nodes, and users can submit their jobs to run within a specific partition. For example, a cluster might have partitions named "GPU" for nodes equipped with GPUs and "standard" for regular computing nodes. Users can then specify the partition they want their job to run in, and Slurm will schedule the job accordingly based on the availability of resources in that partition.
Partition configuration is done by the system administrator, and users interact
with partitions when submitting jobs through the sbatch command by specifying
the desired partition with the --partition option. ORFEO is configured with
four partitions that are named after different machines architecture EPYC,
THIN, GPU, DGX, UPDATE.
Warning
There is no default partition in ORFEO. Each user has to explicitly select where their job will run.
The EPYC partition consists of the 8 nodes equipped with two AMD EPYC 7H12 cpus.
This partition is configured with a maximum runtime of 150 hours (note that your account might be limited to shorter runs) and a default memory per core (cpu in slurm slang) of 1024 MiB. Typical usecases are heavy, highly parallelizable tasks that are not (or cannot) use GPUs.
The Thin partition consists of 12 intel nodes: two equipped with Xeon Gold 6154 and 10 equipped with Xeon Gold 6126 cpus. The main difference in the hardware is the available RAM.
This partition is configured with a maximum runtime of 150 hours (note that
your account might be limited to shorter runs) and a default memory per
core (cpu in slurm slang) of 1024 MiB. Your code will run on all the nodes.
Selection between the kind of node is performed automatically based on the
requested memory. Specific nodes can be asked if desired through the
--nodelist= parameter. Typical usecases are not high parallel codes that
can exploit the higher single core boost frequecy, or workflow that require
a lot of RAM.
The GPU partition consists of the 4 nodes equipped with two Intel Xeon Gold 6226 CPUs and 2 x V100 PCIe.
This partition is configured with a maximum runtime of 18 hours (note that your account might be limited to shorter runs) and a default memory per core (cpu in slurm slang) of 1024 MiB. These GPUs are optimal to play and learn how to use a GPU, perform GPU accelerated calculations like fluid dynamics, and learn how to properly approach a high-end GPU.
The DGX partition consists of the 2 DGX nodes equipped with two AMD EPYC 7H12 cpus and 8 x A100 SXM.
This partition is configured with a maximum runtime of 150 hours (note that your account might be limited to shorter runs) and a default memory per core (cpu in slurm slang) of 1024 MiB. These GPUs are optimal to perform advanced calculations in all fields but using them at their full potential is complicated. By default access is not granted to this queue.
The GENOA partition comprises 13 AMD nodes, each equipped with two AMD EPYC 9374F processors and 512 GB of RAM. Featuring Zen 4 architecture, these nodes offer 64 cores each, making them well-suited for intensive CPU workloads, thanks to their high base clock speed of 3.85 GHz.
The H100 partition consists of three PowerEdge XE9680 nodes, each housed in a 5U chassis weighing 114.05 kg.
Each node is equipped with eight H100 GPUs (80 GiB each), two Intel(R) Xeon(R) Platinum 8480+ processors, and 1024 GiB of RAM.
The GPUs are interconnected via NVLink to an NVSwitch, enabling ultra-fast communication between them with a bidirectional GPU-to-GPU bandwidth of 900 GB/s.
Each node is equipped with eight ConnectX-7 InfiniBand network cards, each supporting a speed of 200 Gbit/s.
This partition is usually empty and is used for maintenance purposes.
Networking¶
Internal connectivity in ORFEO is handled by a 25 Gbit/s Ethernet Network for general TCP/IP and by Infiniband link for Remote Direct Memory Access (RDMA) between the compute nodes with a bandwidth up to 200 Gbit/s.
External connectivity is granted by 10 Gbit/s link to the Padriciano campus and then there are links to LightNet, GARR and commercial ISP link.
Local Storage¶
For regular operations, network storage is used; limited local storage (~300Gb)
is available in the /local_scratch folder.